
deepseek-r1 论文阅度
Published:
DeepSeek R1 的各种亮眼成果,那它到底是怎么训练出来的呢?这背后的训练过程就像一场精心策划的冒险,每一步都至关重要,接下来咱们就一起走进这场训练之旅。
研究目标:用强化学习增强推理能力
背景
大语言模型(如 GPT-4、Claude 等)在推理任务(数学、编程、科学)中表现不错,但过去很多方法依赖大量人工标注数据(监督微调,SFT),成本高且可能限制模型自主推理能力。
目标
探索仅用 ** 强化学习(RL)** 提升推理能力,减少对人工数据的依赖,让模型通过 “试错” 自主学会复杂推理。
两代模型:从纯强化学习到冷启动优化
训练流程总览
为了让大家更直观地了解 DeepSeek R1 的训练过程,这里先给大家呈上一张训练流程图:
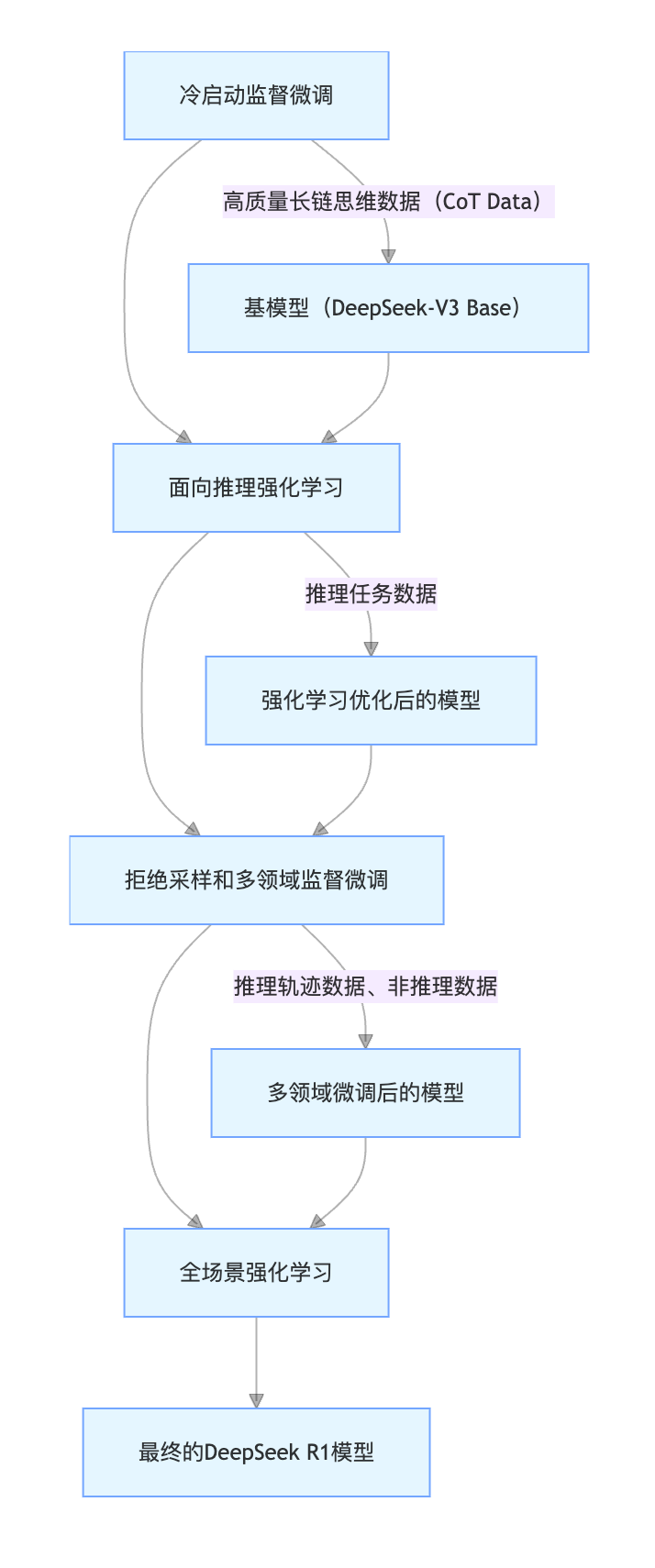
从这张图可以看出,整个训练过程就像一场接力赛,四个阶段环环相扣,每个阶段都在上一阶段的基础上,给模型带来新的提升。
DeepSeek-R1-Zero:纯强化学习的尝试
训练方式
直接对基础模型(DeepSeek-V3-Base)使用Group Relative Policy Optimization(GRPO)算法进行强化学习,不使用任何人工标注数据。
GRPO 算法的核心思想
分组相对策略优化(Group Relative Policy Optimization,GRPO)算法。这个算法就像是给 “推理特训营” 制定了一套独特的训练规则。它通过规则奖励,比如答案准确性、格式一致性等,来驱动模型优化。比如说模型做数学题,答案对了,推理过程格式也很规范,那就能得到很高的奖励分数;要是答案错了,或者格式乱七八糟,奖励分数就很低。模型为了得到更高的奖励,就会不断优化自己的推理策略,让自己在各种推理任务中表现得越来越好。
下面来详细讲讲 GRPO 算法的运作流程:
- 初始策略模型:一开始,会有一个初始策略模型$\pi_{\theta_{init}}$,它就像是一个刚入学的新生,带着一些初始的 “知识”,也就是模型参数,这些参数决定了模型面对问题时会采取怎样的 “行动”,也就是生成怎样的输出。
- 奖励模型:同时,还有一个奖励模型$r_{\varphi}$,它就像一位严格的老师,负责评估模型生成的输出质量。对于模型给出的每一个输出,奖励模型都会根据一定的标准给出一个奖励分数,这个分数反映了输出的好坏程度。
- 任务提示:训练过程中会有一系列的任务提示$D$,这可以理解为老师给学生布置的作业题目。模型需要根据这些提示来生成相应的输出,就像学生要根据题目要求写出答案一样。
- 超参数设定:算法中还涉及一些超参数$\varepsilon, \beta, \mu$,它们就像是游戏规则中的一些设定值,控制着算法的行为,比如学习的速度、对不同情况的重视程度等。
- 迭代优化过程:
- 设置参考模型:在每次迭代开始时,会把当前的策略模型设置为参考模型,这就好比学生在每次做作业前,都会先回顾一下自己之前的学习方法。
- 采样任务提示:从任务提示集合中采样一个小批量的数据$D_b$,就像是老师从众多作业题目中挑选出一部分让学生来做。
- 更新旧策略模型:把当前的策略模型更新为旧策略模型,这一步是为了保存之前模型的状态,以便和新生成的结果进行对比。
- 采样输出:对于每个问题$q$,从旧策略模型中采样$G$个输出,这就像学生面对一道题,尝试用不同的方法去解答,给出多个可能的答案。
- 计算奖励:针对每个采样得到的输出,奖励模型会计算它们各自的奖励,判断这些 “答案” 的好坏。
- 计算优势:通过组相对优势估计来计算每个输出中每个标记的优势$A$。这里的优势可以理解为某个输出相对于其他输出的优势程度,通过这种方式,模型可以知道自己哪种 “解题思路” 更有优势。
- 更新策略模型:模型通过最大化 GRPO 目标函数来更新自己的策略,也就是调整模型的参数,让自己下次能给出更好的输出,就像学生根据老师的反馈,调整自己的学习方法,争取下次做得更好。
- 更新奖励模型:使用重放机制连续训练更新奖励模型,让奖励模型能够不断适应模型的变化,更准确地评估输出质量,就像老师也要不断学习,了解学生的新情况,才能更好地评判学生的表现。
通过这样不断地迭代优化,模型在推理任务上的能力就会越来越强,逐渐成长为一个推理高手。
核心发现
- 模型通过强化学习自发产生了 ** 反思(重新评估步骤)、自我验证、生成长思维链(CoT)** 等复杂推理行为。
- 在数学基准 AIME 2024 上,通过率(pass@1)从初始的 15.6% 提升到 71.0%,使用多数投票后达到 86.7%,接近 OpenAI 的 o1-0912 模型。
局限性
模型输出的结果可能会乱成一锅粥,就像一个刚学写字的小朋友,写出来的字歪歪扭扭,大小不一,还可能中英文混着,格式也乱七八糟,完全没有条理。而且,这样训练出来的模型也缺乏人类友好的推理模式。
DeepSeek-R1:引入冷启动数据的优化版
改进点
- 冷启动阶段:先用少量高质量 “思维链” 数据(数千条)对模型进行微调,解决纯强化学习初期的不稳定性,提升生成内容的可读性(如强制格式规范、添加总结)。
- 多阶段训练:冷启动微调 → 推理强化学习 → 拒绝采样生成新 SFT 数据(含写作、事实问答等通用任务)→ 全场景强化学习(兼顾推理和人类偏好,如无害性)。
拒绝采样和多领域监督微调
当面向推理的强化学习达到收敛状态后,就来到了拒绝采样和多领域监督微调阶段。这一步就像是让已经在推理方面有一定成绩的学生,不仅要在擅长的科目上继续保持,还要学习其他科目,变得更全面。
拒绝采样技术在这个阶段发挥了重要作用。它就像是一个 “严格的筛选器”,从模型生成的响应中筛选出正确的推理轨迹。比如说模型做了很多数学题,生成了一堆解答过程,拒绝采样会把那些错误的、不合理的解答筛选掉,只留下正确的、高质量的推理轨迹。这样就能确保后续训练数据的质量,进一步提升模型的推理能力。
多领域监督微调则是让模型接触更多领域的数据。之前模型主要在推理相关的任务上进行训练,现在要让它在写作、事实问答等非推理任务上也能表现出色。怎么做呢?就是利用混合数据集,把前面筛选出来的正确推理轨迹和非推理数据(比如说 DeepSeek-V3 的 SFT 数据集中关于写作、翻译等方面的数据)结合起来,对模型进行两轮微调。通过这两轮微调,模型在多个领域的性能都得到了提升,变得更加 “多才多艺”,不再只是一个 “推理小能手”,在其他方面也能应对自如了。
全场景强化学习
这是 DeepSeek R1 训练的最后一个阶段,就像是把已经多才多艺的学生送到现实世界中,去适应各种复杂的场景,并且要符合社会的价值观和人们的期望。
在全场景强化学习阶段,DeepSeek 团队做了很多工作。首先是收集人类偏好数据,比如说人们希望模型在回答问题时,语言要礼貌、温和,不要输出有害或者不恰当的内容。然后,通过强化学习技术,让模型在开放域问答、长文本理解等复杂场景中表现得更加稳健。在这个过程中,对于推理任务,还是沿用之前的规则奖励,保证模型在推理方面的能力不会下降;对于通用任务,就使用神经奖励模型来评估人类偏好,比如模型给出的最终答案是否实用,整个回答是否无害。
为了让模型适应多样化的需求,团队还采用了多提示分布训练。就是给模型提供不同场景的提示数据,比如用户不同类型的查询、角色扮演的场景等。模型在面对这些多样化的提示时,不断调整自己的策略,最终学会在各种场景下都能给出符合人类期望的回答。经过这一阶段的训练,模型就像是一个既聪明又懂事的孩子,不仅推理能力强,还能在各种场景下和人类友好互动,完全贴合人类的需求啦。
训练效果
- 推理能力接近 OpenAI-o1-1217,例如在 AIME 2024 上 pass@1 达 79.8%,MATH-500 达 97.3%。
- 编程任务中,Codeforces 评级达 2029,超过 96.3% 人类选手,显示专家级水平。
模型蒸馏:让小模型也能强大
- 将大模型(DeepSeek-R1)的推理能力 “蒸馏” 到更小的模型中,降低计算成本,便于应用。
- 用 DeepSeek-R1 生成的 80 万条推理数据,微调 Qwen、Llama 等开源小模型(如 1.5B、7B、32B 参数)。
效果
- 蒸馏后的 7B 模型在 AIME 2024 上达 55.5%,超过开源的 QwQ-32B-Preview 模型。
- 32B 模型在 MATH-500 上达 94.3%,接近 OpenAI-o1-mini,且计算效率更高。
数据集的构成
冷启动监督微调阶段
主要使用高质量的长链思维数据(CoT Data),这些数据规模大概在数千条。数据来源一部分是人工精心设计的示例,另一部分则来自 DeepSeek-R1-Zero 输出后的再处理,并且都进行了多语言对齐处理,确保格式规范,比如统一使用
面向推理强化学习阶段
此阶段用到的是大量推理任务数据,像数学、代码、逻辑等领域的题目及解答。这些数据的答案都是可以自动验证的,例如数学题可以通过答案是否精确匹配来判断对错,代码可以通过单元测试等方式来验证。模型在不断处理这些数据的过程中,借助强化学习的规则奖励机制,持续优化自己的推理策略,提升在这些复杂推理任务上的能力。
拒绝采样和多领域监督微调阶段
这一阶段的数据集较为丰富,由两部分组成。一部分是通过拒绝采样从前面强化学习收敛后的模型响应中筛选出的正确推理轨迹,大概有 60 万条,这些数据进一步精炼了模型的推理能力;另一部分是复用 DeepSeek-V3 的 SFT 数据集中非推理相关的数据,例如写作、事实问答、翻译等方面的数据,约 20 万条。这两部分数据加起来共约 80 万样本,用于对模型进行两轮微调,让模型在保持推理能力的同时,扩展在其他领域的通用性。
全场景强化学习阶段
虽然没有明确特定新的大规模数据集类型,但在这个过程中,会结合不同场景的提示数据,如用户各种类型的查询、角色扮演的场景描述等。这些提示数据就像现实世界中的各种复杂问题场景,模型通过不断接触和处理这些多样化的提示,学会在各种真实场景下给出符合人类期望和需求的回答。
这篇论文展示了纯强化学习在大模型推理中的潜力,通过两代模型的迭代和蒸馏技术,证明了无需大量人工数据也能提升推理能力,且小模型可通过蒸馏获得接近大模型的性能。这为开源社区提供了更经济高效的推理模型方案,也为未来自主推理模型的发展奠定了基础。
注:本文是基于 DeepSeek R1 论文的总结,如有错误或遗漏,欢迎指正。 原文链接:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

